
I am Zhangyang Qi (Nicky name: Alex Chi, Chinese name: 戚张扬), a third-year Ph.D. student in computer science at The University of Hong Kong (HKU) since Sep 2022, advised by Prof. Hengshuang Zhao and Prof. Yizhou Yu. I also work as a Research Intern at Shanghai AI Laboratory, supervised by Jiaqi Wang and Tong Wu.
My research interest includes multimodal language models for 3D scene understanding and interactions.
- Video language models
- 3D point language models
- Large language models
- 3D scene understanding
I am set to graduate in August 2026 and am actively exploring opportunities in my career. I welcome any inquiries to reach out to me via WeChat: qi-zhangyang. Attached are my English Resume and Chinese Resume for your reference.
🔥 News
- 2024.03: 🎉🎉 GPT4Point has been accept by CVPR 2024.
- 2023.10: 🎉🎉 OCBEV has been accept by 3DV 2024.
- 2022.09: 🎉🎉 Join HKU as a Ph.D. student.
- 2022.07: 🎉🎉 Got bachelor’s degree from HIT with Top Ten Outstanding Students and Outstanding Graduate.
📖 Educations
- 2022.09 - present, Ph.D. in Computer Science, The University of Hong Kong (HKU).
- 2018.08 - 2022.07, Bachelor in Information Engineering, Harbin Institute of Technology (HIT).
📝 Publications
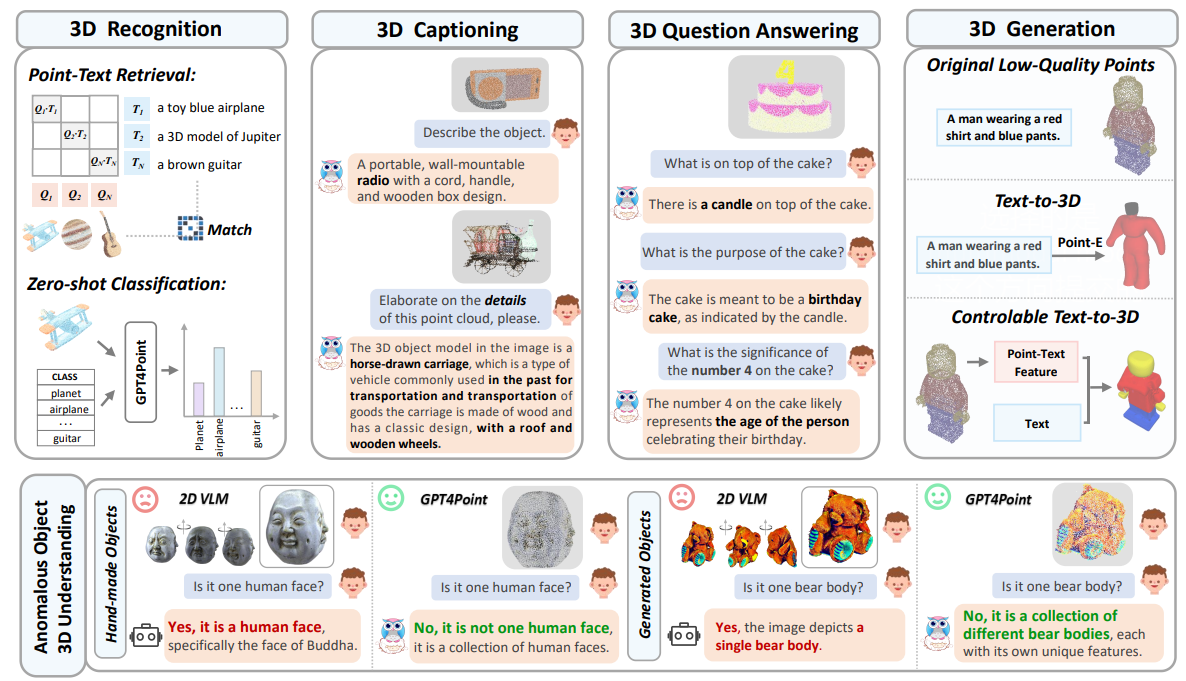
GPT4Point: A Unified Framework for Point-Language Understanding and Generation
Zhangyang Qi, Ye Fang, Zeyi Sun, Xiaoyang Wu, Tong Wu, Jiaqi Wang, Dahua Lin, Hengshuang Zhao
- The first object-level 3D point cloud multimodal large language model, unifying both point cloud understanding and generation tasks.
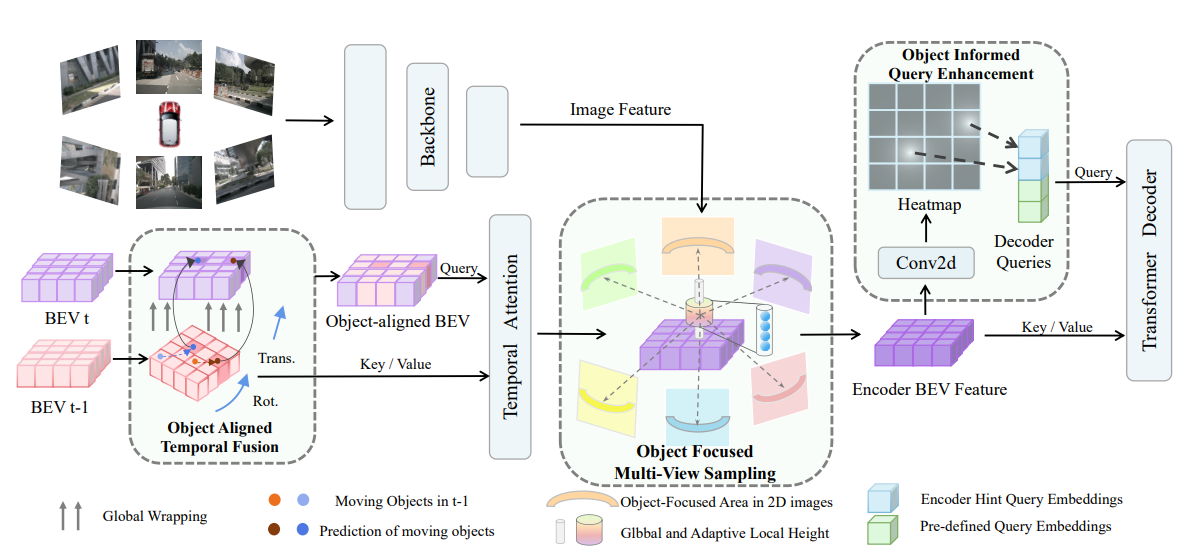
OCBEV: Object-Centric BEV Transformer for Multi-View 3D Object Detection
Zhangyang Qi, Jiaqi Wang, Xiaoyang Wu, Hengshuang Zhao
- An object-centric BEV (Bird’s Eye View) autonomous driving 3D object detection framework, achieving performance improvements on the nuScenes dataset with half the training data.
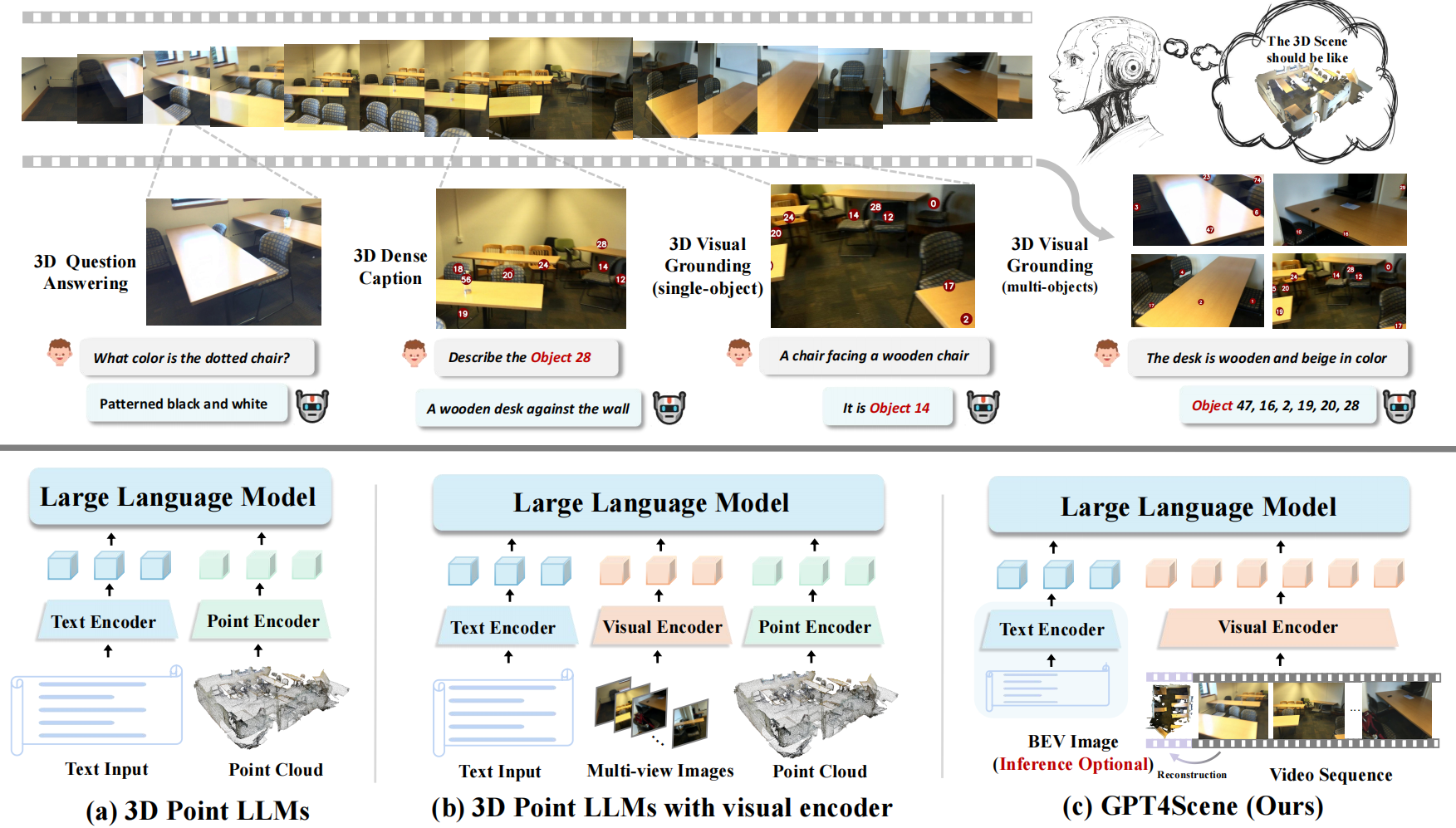
GPT4Scene: Understand 3D Scenes from Videos with Vision-Language Models
Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, Hengshuang Zhao
- The first to utilize a video-based large language model for indoor scene understanding.

Tailor3D: Customized 3D Assets Editing and Generation with Dual-Side Images
Zhangyang Qi, Yunhan Yang, Mengchen Zhang, Long Xing, Xiaoyang Wu, Tong Wu, Dahua Lin, Xihui Liu, Jiaqi Wang, Hengshuang Zhao
- Our work introduces a novel framework for 3D object generation and editing, leveraging dual-view image manipulation.
🌐 Experiences
Shanghai AI Laboratory, Shanghai, China
2022.07 – Present
- Research Intern, Supervisors: Jiaqi Wang, Tong Wu
- Research on 3D and video language models, developing the GPT4Point, GPT4Point++, and GPT4Scene.
- Curated training data for InternLM-XComposer series and V3Det dataset.
Tencent PCG, Shenzhen, China
2021.12 – 2022.05
- Research Intern
- Built CLIP-based cross-modal alignment via contrastive learning for image-text matching.
- Designed joint training paradigms enhancing embedding alignment in multimodal retrieval.
🎖 Awards
- Hong Kong PhD Fellowship Scheme (HKPFS), 2022.
- HKU Presidential Scholarship (HKUPS), 2022.
- Top Ten Students of Harbin Institute of Technology, 2021.
- National Scholarship, 2020.
💻 Professional Services
- Conference reviewer: CVPR’24,25, ICCV’25.
- Teaching assistant: DASC7606: Deep Learning (Graduate course @ HKU), 2023 Spring, 2024 Spring, 2024 Fall.